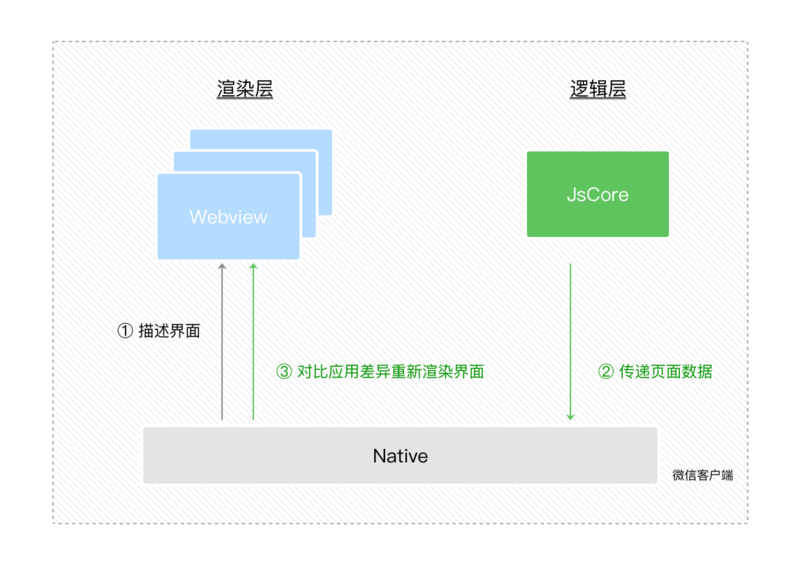
百度智能小程序接入自然搜索
初梦小程序
小程序资讯
2019-07-09
149

百度智能小程序为开发者提供了全面开放的自然百度搜索接入能力。本篇文章将主要面向小程序开发者从以下几个方面介绍如何接入自然搜索:
一、资源收录,介绍通过Web化实现小程序的破壳检索收录;
二、Web化预览与调试,讲解开发者如何预览和调试Web小程序;
三、搜索引擎优化,介绍小程序开发中应该注意哪些搜索引擎优化手段;
四、其他开发建议,列举小程序开发中,考虑Web化实现,应该注意哪些实现问题。
在介绍之前,我们先来了解什么是小程序接入自然搜索。
通过接入百度搜索生态,在百度 App 中(10.10或以上版本)无需用户精准搜索小程序名称,只要检索到与搜索内容相关的小程序页面,该小程序结果即会展示在百度搜索结果页面中,为用户提供更加精准便捷的服务。
同质内容情况下,搜索会优先展现智能小程序页面。当智能小程序某页面被用户检索到,其展现形式会有小程序标签,用户在百度App(10.10或以上版本)点击该条搜索结果,即可打开智能小程序。开发者只需要进行简单的配置工作,就可以使自己开发的智能小程序被百度搜索收录、分发。
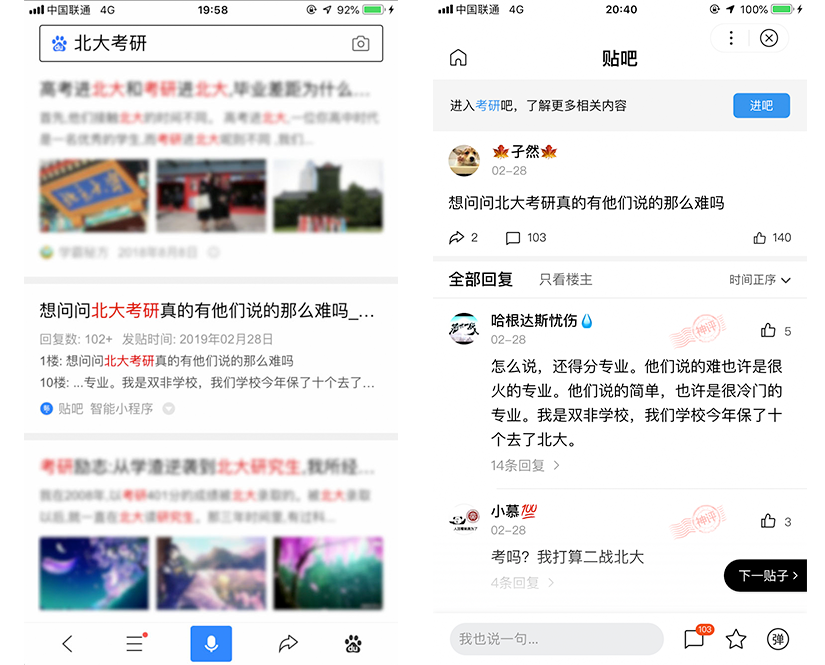
举个例子: 在百度 App 中搜索 “北大考研”,自然搜索结果中,可以看到百度贴吧小程序的相关搜索结果。 点击该条结果,就会直接打开百度贴吧小程序相应页面
那么百度智能小程序是如何接入自然搜索的呢?接下来的章节我们会详细介绍小程序接入自然搜索的原理以及对于小程序开发者,要接入自然搜索应该关注哪些问题。
一、资源收录
在 Web 生态中,搜索引擎如何发现并收录资源大家并不陌生。爬虫通过抓取 Web 网页,能够很好的解析页面内容,并为其建立索引。那么作为依托于客户端形态存在的小程序,又是如何实现资源收录的呢?
答案是,既然 Web 爬虫技术已经相对成熟,只要将小程序转换为一个 Web 版本,即可轻松借助已有的爬虫能力实现小程序页面的收录。到这里,今天的主角就要隆重登场了 —— Web 化小程序
Web 化小程序是百度小程序的 Web 版本。每个 Web 化小程序都是一个单页面应用站点,可以通过唯一对应的 URL 在浏览器打开。Web 化小程序与对应的客户端打开的小程序内容、样式和交互行为基本一致。
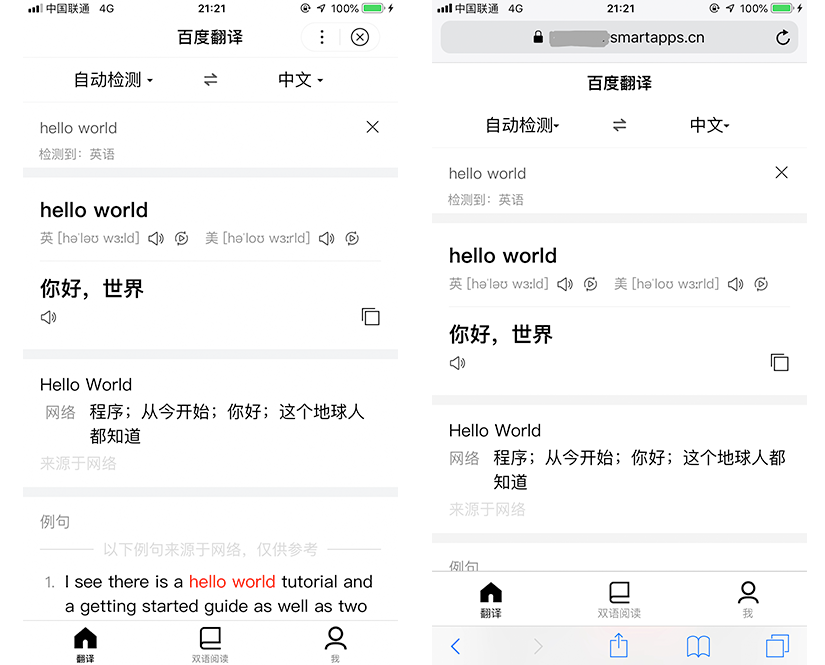
以百度翻译小程序为例,下图为百度翻译小程序在百度 App 中打开和它的 Web 化小程序在 safari 浏览器打开的效果:
那么 Web 化小程序是如何生成的呢?
百度智能小程序具有自动生成 Web 化的能力,在小程序发布时,后台会自动为每个小程序生成一份 Web 化小程序。也就是说 Web 化对小程序开发者来说是透明的,开发者几乎不用做额外的适配即可完成转换(当然,由于H5与客户端天然存在的差异,我们仍有一些开发建议希望开发者能够关注,后面会详细介绍)。
有人问:想让爬虫认识至于那么认真吗?有个 HTML 就够了,还要和客户端小程序样式和交互保持一致?事实上,随着SPA应用的大量普及,现代爬虫如果仅通过解析静态 HTML ,无法充分获取有效页面内容。因此 爬虫的抓取过程,会渲染页面,并根据页面的动态数据和样式布局等信息更好的理解页面内容。也就是说,爬虫看到的页面和我们看到的页面是一模一样的。
在百度开发者工具 2.2.4 以上版本,默认开启 Web 化。之前版本的工具需要手动打开 Web 化开关。对于之前未开启 Web 化的小程序,只要升级工具到最新版本,重新发布,即可自动开启。
当有小程序发布后,爬虫会通过自主发现的方式收录 Web 化小程序的各个页面,为其建立索引。
除了自主发现的资源收录方式,如果开发者想要获取更高时效的资源收录效率,还可以通过主动提交资源列表,即 sitemap 的方式实现天级和周级资源收录。sitemap 提交详见官方文档《接入自然搜索结果 - 提交sitemap 》
对于在百度已收录了 H5 站的资源,也可以通过配置 H5 域名和提交 H5 与小程序页面映射规则的方式替换原 H5 页面收录结果继承已有权重。具体提交方式详见官方文档《接入自然搜索结果 - 配置URL映射规则》
二、Web 化预览与调试
开发者工具提供了访问 Web 化页面效果的方式。
预览 Web 化前,请确保服务器域名配置中 request 域名已配置,否则接口数据请求不能正常返回。 配置方式:小程序后台-设置-开发设置-服务器域名-request的合法域名
在开发者工具中,登录状态下,点击“预览”按钮,弹出窗中切换到 “WEB预览” Tab 可以预览 Web 化的效果。可直接扫码或通过手机浏览器查看。
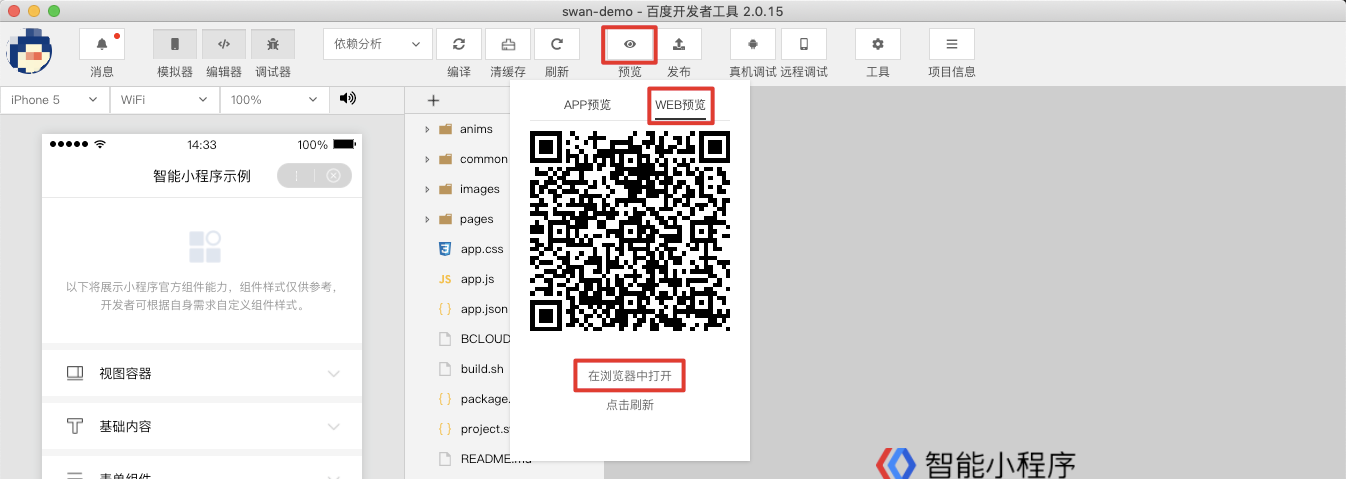
通过点击上图中 “在浏览器中打开” 可以看到 Web 化的页面 URL。 Web 化的页面 URL 地址规则如下:

每个小程序都有唯一的子域名;
URL 中 path 和 query 部分和小程序页面中的 path 和 query 一致。比如:上例对应的小程序页面在百度App中的打开路径即为/pages/detail/index?id=1;
如URL中没有指定 path 和 query,默认跳转首页。
预览环境的 URL 后有 appKey 参数,正式发布后,Web 化线上地址不包含 appKey 参数。
三、搜索引擎优化
与普通的 Web 站点一样,Web 化小程序也可以通过一些搜索引擎优化(SEO)手段获取更准确的相关性排名结果。
1. 设置页面基础信息
正如在 H5 开发中,会在 HTML 中添加 title、meta description、meta keywords 标签,声明页面相关内容,小程序的页面信息声明通过设置页面基础信息实现。
页面基础信息包括页面的标题、摘要、关键词、页面主图、资源发布时间等,以下仅介绍几个主要信息,更多设置要求详见官方文档《API - 页面基础信息》:
标题(Title):能够更加快速洞察页面内容,了解该结果与需求的相关性,通常是用来决定用户点击哪个结果的主要信息。所以,使用高质量的页面标题对小程序来说至关重要;
摘要(Description):小程序首页、栏目页、分类页的摘要非常重要,因为有可能在搜索结果中直接被用户看到,影响到用户是否选择点击查看详情;
关键词(Keywords):小程序开发者给网站某个页面设定的词汇,以便让搜索引擎更好地理解页面价值。keywords代表了小程序主题内容,无论是首页、内页还是栏目页,关键词一般都代表的是当前页面或者栏目内容的主体。开发者根据实际情况设置即可;
页面主图(Image):页面中的主体图片地址,必须是页面中真实展示的与页面主体内容相关的图片。有效的图片描述可能会在搜索结果中展示,给用户更直观友好的体验,提升用户点击率。
页面基础信息通过小程序 API swan.setPageInfo 设置,使用示例如下:
Page({
onShow() {
swan.setPageInfo({
title: 'Win10控制面板在哪?怎么找出来-百度经验',
keywords: 'Win10控制面板在哪?win10面板,电脑软件,电脑,游戏/数码',
description: 'Win10控制面板在哪?升级了Wi10系统发现:电脑上的【控制面板】不见了,教大家怎么把消失的【控制面板】找回来。',
image: 'https://example.com/myphoto.jpg'
...
});
}));
更多详细使用方式介绍见官方文档《API - 页面基础信息》
页面基础信息的设置粒度是页面级的,因此强烈建议在 Page 的 onshow 生命周期中调用,以保证每次页面切换都能有效设置当前页的页面基础信息。
setPageInfo 在 Web 化的内部实现其实就是将调用参数动态设置为 HTML 标签中的 title、meta description、meta keywords 标签,以及符合 The Open Graph protocol 的 meta 标签。 因此,如要调试调用 setPageInfo 之后,页面基础信息是否设置成功,可以检查 Web 化页面渲染后的 HTML Element 中是否成功设置了这几个标签。Web 化页面预览方法将在第二章节介绍。
比如上例中的设置结果如下:
<!DOCTYPE html><html><head> <title>Win10控制面板在哪?怎么找出来-百度经验</title> ... <meta name="description" content="Win10控制面板在哪?升级了Wi10系统发现:电脑上的【控制面板】不见了,教大家怎么把消失的【控制面板】找回来。"> <meta name="keywords" content="Win10控制面板在哪?win10面板,电脑软件,电脑,游戏/数码"> <meta property="og:description" content="Win10控制面板在哪?升级了Wi10系统发现:电脑上的【控制面板】不见了,教大家怎么把消失的【控制面板】找回来。"> <meta property="og:image" content="https://example.com/myphoto.jpg"></head><body>...</body></html>
swan.setPageInfo 中设置的字段除了在接入自然搜索场景下会被用到,在接入百度信息流中也起到至关重要的作用,详见官方文档 《信息流流量接入》另外,swan.setPageInfo API 不仅用于在流量接入场景下的页面内容声明,在客户端小程序实现中,页面基础信息也会被用作页面分享、页面收藏时的摘要信息。
2. 链接跳转
页面中的链接跳转对爬虫收录有很重要的价值。 对于普通 H5,页面跳转的方式通常有两种:a 标签跳转和 window.location.href 赋值方式跳转。前者直接设置在 HTML 标签中,发现效率和准确性相较后者友好很多。
同理,在小程序中,设置页面跳转的方式对应的也有两种:
navigator 组件,标签式声明
导航类 API,通过用户事件等方式触发调用
为了有效的被爬虫发现,我们强烈建议在两者都能满足需求的情况下,使用 navigator 组件的方式声明链接。
✅ 推荐跳转示例:
<navigator url="/pages/detail/detail">点我跳转</navigator>
❎ 不推荐跳转示例:
<button bindtap="jump">点我跳转</button>Page({
jump() {
swan.navigateTo({
url: '/pages/detail/detail'
});
}
...})3. 避免使用 webview 组件
为了方便小程序开发,很多开发者会选择通过 webview 组件嵌套 H5 页面的方式实现小程序。 使用 webview 组件嵌套方式实现的小程序对于爬虫抓取是不友好的。因此,我们不推荐使用这种方式开发小程序。
4. 游客模式兼容
由于爬虫的访问环境没有账号登录模拟,在任何页面都将以游客模式访问(游客模式下调用 swan.login 会执行 fail 回调)。因此,开发者希望收录的页面,应考虑对游客模式的兼容。对于无用户信息依赖的页面不添加强制登录的逻辑,用户信息获取失败时仍然展示有效内容。
例如: 在一个博客论坛的博文页,只有评论功能需要在用户登录态完成。那么当在未登录态访问该页面时,应该正常展示文章主体,仅在用户点击评论时再要求登录。而非在页面进入时就强制登录才可正常浏览。
5. 避免页面间访问顺序依赖
由于小程序一般外露入口较集中,比如后续页面都只会通过首页跳转访问,小程序开发者通常很容易忽略页面之间访问的独立性,造成页面实现逻辑与访问路径过于耦合的情况。例如: 在首页请求数据信息后,通过 setStorage 存储本地,并在跳转二级页时读取 storage 中存储的数据,不做任何判空处理直接展示。
考虑 Web 化小程序被爬虫抓取的情况,每个页面都是独立入口访问的。所以,应该避免这种耦合访问顺序的写法,添加必要的兼容处理。 可以在小程序开发完成时,通过单独预览每个 Web 化页面的方式检查是否符合要求。
代码示例:
首页:
Page({
onShow() {
swan.request({
url: 'https//example.com/api/data',
success: function (res) {
...
swan.setStorageSync('remote-data', res.data);
}
});
}});
二级页:
// badPage({
onShow() {
let data = swan.getStorageSync('remote-data');
this.render(data);
}});// betterPage({
onShow() {
let data = swan.getStorageSync('remote-data');
if (!data) {
swan.request({
url: 'https//example.com/api/data',
success: function (res) {
...
data = res.data }
});
}
this.render(data);
}});
四、其他开发建议
除了搜索引擎优化相关建议,下面是针对开发者的一些额外的开发建议。
1. 如何在运行时识别 Web 化环境
在代码中,可以通过 API getSystemInfo 判断是否为 Web 化 环境。Web 化环境下,调用swan.getSystemInfo()得到的系统信息中,platform 值为“web”。
通常情况下,为保证抓取内容相关性和用户体验一致性,禁止开发者区分 Web 化环境做差异化实现。
Web 化环境标识主要服务于诸如区分环境统计等需求场景。
2. 避免使用新的ESNEXT语法
考虑到 Web 化可能会在各种浏览器版本打开,源码实现时尽量避免使用过新的 ESNEXT 特性。
3. 禁止为 HTML、BODY 标签以及小程序框架组件生成的标签设置样式
为 HTML、BODY 标签和小程序组件标签设置样式,可能污染框架样式,造成页面样式异常,影响爬虫抓取。
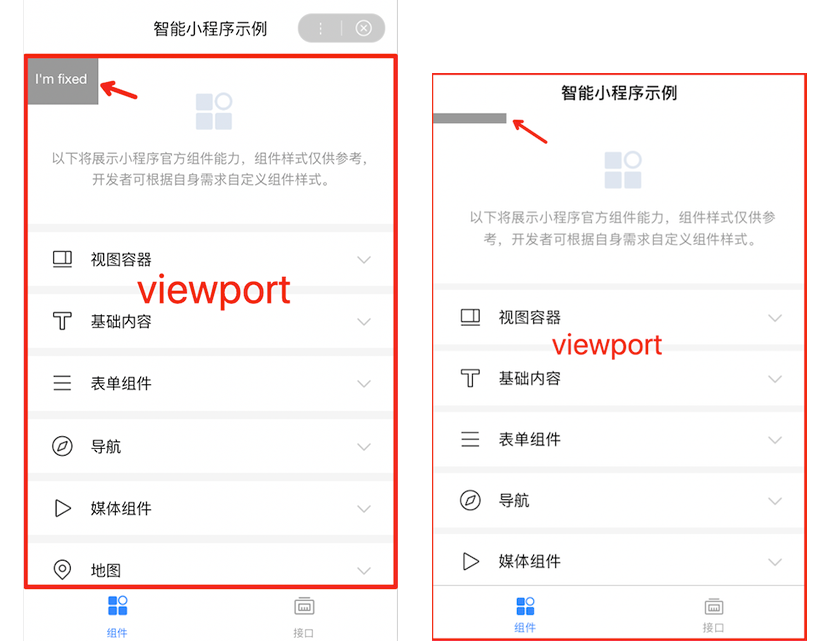
4. Fixed 布局样式
由于 Web 化中 header 和 tabBar 是由 H5 实现的,包含在窗口中;而小程序中的视窗是除去 header 和 tabBar 的部分。两种视窗的差异会导致 fixed 定位的差异。因此开发中尽量避免使用fixed定位方式。如图:
总结
百度智能小程序提供了接入自然搜索的能力,后台会通过自动将小程序生成为 Web 化小程序的方式检索和收录小程序资源。除了搜索引擎自主发现,开发者还可以通过提交 sitemap 和 URL 映射规则的方式实现更高效的资源收录。
小程序开发过程中通过搜索引擎友好的实现方式可以提高自然搜索结果排名,提高用户搜索体验。
更多百度小程序流量接入权益说明,请在百度智能小程序官方文档中查看《百度智能小程序流量接入》





热门文章